2023-11-19 Wandering Lines
Description
Convert an image into a series of wandering lines where each wandering line is one of N colors.
Images


Plotter Preview
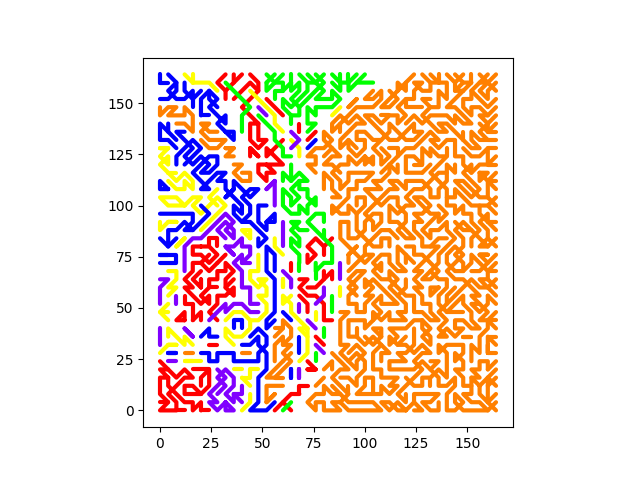
Code
from gcode2dplotterart import Plotter2D
import cv2
import numpy as np
from imutils import resize
from math import floor
from typing import List, Tuple
from random import shuffle
from collections import namedtuple
from sklearn.cluster import KMeans
def hex_to_rgb(hex: str):
hex = hex.lstrip("#")
return tuple(int(hex[i : i + 2], 16) for i in (0, 2, 4))
Point = namedtuple("Point", ["row", "col"])
"""
Preface - numpy and cv2 are still a bit alien to me. The code here could be done better.
1. Take in an image.
2. Grayscale all of the pixels so that each pixel is represented by a number from 0 to 255.
3. Bucket the pixels such that
- 0 -> A becomes 0
- A -> B becomes 1
- B -> C becomes 2
- C -> 255 becomes 3
4. Start with a random pixel in the image that hasn't been plotted.
5. Add this point to the path
6. Look to the neighboring pixels
- If a neighboring pixel, order randomly chosen, is of the same color, add it to the path.
- If the neighboring pixel hasn't been added to a path before, repeat step 6.
- If the neighboring pixel has been added to a path before, repeat step 4.
- If there are no neighboring pixels of the same color, repeat step 4.
7. Continue until all points of all colors are plotted.
Note
- Make sure that the combination of X_SCALE, Y_SCALE, and the resized image aren't too big for the plotter area.
"""
# These numbers can be changed in combination with the image size. Adds a bit of spacing since I use thicker
# pens and they'd overlap.
X_PIXELS_PER_PLOTTER_UNIT = 1 / 4
Y_PIXELS_PER_PLOTTER_UNIT = 1 / 4
# This function does not seem to bucket into each color.
def evenly_distribute_pixels_per_nth_percent_of_grayscale_range(
img: cv2.typing.MatLike, n: int
) -> List[List[int]]:
"""
Take the range of grayscale (0 -> 255) and bucket it such that n% of the range is a bucket.
Arg:
`img` : cv2.typing.MatLike
The image to process
`n` : Number of colors to distribute pixels into
Returns
` img` : List[List[int]]
Image mapped to n colors
"""
bucket_segments = np.linspace(
0, 256, n + 1
) # Use linspace to create evenly spaced buckets
grayscale_buckets = np.digitize(img, bucket_segments[:-1]) - 1
print(grayscale_buckets)
max_val = np.amax(grayscale_buckets)
print(max_val)
min_val = np.amin(grayscale_buckets)
print(min_val)
return grayscale_buckets
# Something is off here. Might not be the kmeans algo, but something is.
def kmeans_color_reduction(img: cv2.typing.MatLike, n: int) -> List[List[int]]:
colors = [hex_to_rgb(color_layer["color"]) for color_layer in COLOR_LAYERS]
h, w = img.shape
image_reshaped = img.reshape((h * w, 1))
# Use KMeans to find the closest colors
kmeans = KMeans(n_clusters=len(colors), random_state=0, n_init=10)
kmeans.fit(image_reshaped)
labels = kmeans.predict(image_reshaped)
# Replace each pixel with its closest color index
quantized_image_array = labels.reshape((h, w))
return quantized_image_array
def evenly_distribute_pixels_per_color(
img: cv2.typing.MatLike, n: int
) -> List[List[int]]:
"""
Ensures that each color has the same number of pixels.
Arg:
`img` : cv2.typing.MatLike
The image to process
`n` : Number of colors to distribute pixels into
Returns
` img` : List[List[int]]
Image mapped to n colors
"""
total_pixels = img.size
pixel_bins = []
histogram, bins = np.histogram(img.ravel(), 256, (0, 256))
count = 0
for pixel_value, pixel_count in enumerate(histogram):
if count >= total_pixels / (n):
count = 0
pixel_bins.append(pixel_value)
count += pixel_count
return np.subtract(np.digitize(img, pixel_bins), 0)
def resize_image_for_plotter(filename: str) -> List[List[int]]:
img = cv2.imread(filename)
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# The following math will ensure that the image is scaled to the plotter size and the remaining math
# throughout the program will work.
plotter_ratio = "landscape" if plotter.width > plotter.height else "portrait"
# It appears shape is (columns, rows)
img_ratio = "landscape" if img.shape[1] > img.shape[0] else "portrait"
if (
plotter_ratio == "landscape"
and img_ratio == "landscape"
or plotter_ratio == "portrait"
and img_ratio == "landscape"
):
img = resize(img, width=floor(plotter.width * X_PIXELS_PER_PLOTTER_UNIT))
elif (
plotter_ratio == "portrait"
and img_ratio == "portrait"
or plotter_ratio == "landscape"
and img_ratio == "portrait"
):
print("resizing height")
img = resize(img, height=floor(plotter.height * Y_PIXELS_PER_PLOTTER_UNIT))
print("resized to ", img.shape)
return img
plotter = Plotter2D(
title="Horizontal Line Art",
x_min=0,
x_max=240,
y_min=0,
y_max=170,
feed_rate=10000,
output_directory="./output",
handle_out_of_bounds="Warning", # It appears that some points end up outside of bounds so scale down.
)
# Note to self - I'm currently using the K-Means Algorithm to handle the colors.
# The `color` key below should match the original image's colors to result in successful clustering.
# The title is the type of marker used to plot that.
COLOR_LAYERS = [
{"color": "#ff0000", "title": "Red"},
{"color": "#ff8000", "title": "Orange"},
{"color": "#ffff00", "title": "Yellow"},
{"color": "#00ff00", "title": "Green"},
{"color": "#0000ff", "title": "Blue"},
{"color": "#8000ff", "title": "Purple"},
]
for index, layer in enumerate(COLOR_LAYERS):
plotter.add_layer(layer["title"], color=layer["color"], line_width=3)
input_filename = "test.jpg"
# Works with color PNGs exported from Lightroom and Photoshop. Could learn some more about reading images
resized_image = resize_image_for_plotter(input_filename)
color_reduced_image = kmeans_color_reduction(resized_image, n=len(COLOR_LAYERS))
def get_neighboring_points(row_index: int, col_index: int) -> List[Tuple[int, int]]:
"""
Gets the neighboring points of a given point. The neighboring points are shuffled so that the order
in which they are checked is random. Will not return points outside of teh plotter bounds.
Args:
`row_index` : int
The row index of the point
`col_index` : int
The column index of the point
Returns:
`neighboring_points` : List[Tuple[int, int]]
The neighboring points, in the format of `(row_index, col_index)`.
"""
total_rows, total_cols = color_reduced_image.shape
neighboring_points = []
for row in range(-1, 2):
for col in range(-1, 2):
if row == 0 and col == 0:
continue
if (
row_index + row < 0
or row_index + row + 1 >= total_rows
or col_index + col < 0
or col_index + col + 1 >= total_cols
):
continue
neighboring_points.append(Point(row_index + row, col_index + col))
shuffle(neighboring_points)
return neighboring_points
def add_path_to_plotter(path: List[Point], color: str):
"""
The plotter expects the points to be in the format of (x, y) and the image is in the format of (row, col)
Additionally the image was scaled down to get less lines, now we need to scale it back up to take the total
space of the plotter.
"""
scaled_path = [
(col / Y_PIXELS_PER_PLOTTER_UNIT, row / X_PIXELS_PER_PLOTTER_UNIT)
for row, col in path
]
plotter.layers[COLOR_LAYERS[current_color_index]["title"]].add_path(scaled_path)
remaining_points_to_process = set()
for row_index, row in enumerate(color_reduced_image):
for col_index, value in enumerate(row):
remaining_points_to_process.add(Point(row_index, col_index))
current_point = remaining_points_to_process.pop()
current_path = [current_point]
current_color_index = color_reduced_image[current_point.row][current_point.col]
while len(remaining_points_to_process) > 0:
potential_next_points = get_neighboring_points(
row_index=current_point.row, col_index=current_point.col
)
for potential_next_point in potential_next_points:
current_point = None
if (
color_reduced_image[potential_next_point.row][potential_next_point.col]
== current_color_index
):
current_point = potential_next_point
if current_point in remaining_points_to_process:
# Prefer a point that hasn't been added to a path. This should make paths, on average, longer.
break
if current_point is None:
add_path_to_plotter(current_path, current_color_index)
current_point = remaining_points_to_process.pop()
current_path = [current_point]
current_color_index = color_reduced_image[current_point.row][current_point.col]
continue
if current_point and current_point not in remaining_points_to_process:
current_path.append(current_point)
add_path_to_plotter(current_path, current_color_index)
current_point = remaining_points_to_process.pop()
current_path = [current_point]
current_color_index = color_reduced_image[current_point.row][current_point.col]
continue
if current_point and current_point in remaining_points_to_process:
current_path.append(current_point)
remaining_points_to_process.remove(current_point)
continue
plotter.preview()
plotter.save()